最近在阅读《大规模Web服务开发技术》一书,作为练习和鞭策,决定系统地写一写博客,加深理解。本文用Perl实现了可变字节码算法,对递增的整数序列的文本进行了压缩,压缩率能达到59%。
##可变字节码的定义
1 | 数值 32位二进制 可变字节码 |
可变字节码,将整数序列中的冗余的高位0都去掉,其中130的可变字节码为00000001 10000010,前面8位中的1表示1128,后面8位中最高位的1表示,这是最终的一个字节,代表数字的结束。
所以130 = 1128 + 2 (最后字节中的10),而 5 = 101(二进制)
可以看出,数值越小,可变字节码位数越少。因此对于递增的整数序列[1,2,12,20,39],可以只存储相邻值的差,从而减少了数值的大小。处理后变为[1,1,10,8,19]
##Perl实现的原理
###测试数据的生成
data_gen.pl > data.txt
1 | #!/usr/bin/perl |
###压缩
- 对输入的数值n,与128比较。
- 小于128,则直接用pack函数输出二进制到文件中;
- 大于128,则循环,将n%128的结果插入到数组的开头(unshift);
- 最后,在数组的最后一位加上128,表示这是最终的一个字节。
并将数组pack成字符(1个4Byte的int,被压缩成了2Byte的二进制),输出到二进制文件中
encode.pl程序如下:
./encode.pl data.txt > data.bin
1 | #!/usr/bin/perl |
###解压
- 对输入的二进制流进行unpack
- 数值 = 高8位*128 + 低8位-128 (减去结束字节的标志)
- 整数序列中[a,b,c,d],还原后变成[a,a+b,(a+b)+c,(a+b+c)+d]
./decode.pl data.bin > data.restore
1 | #!/usr/bin/perl |
###压缩的效果图
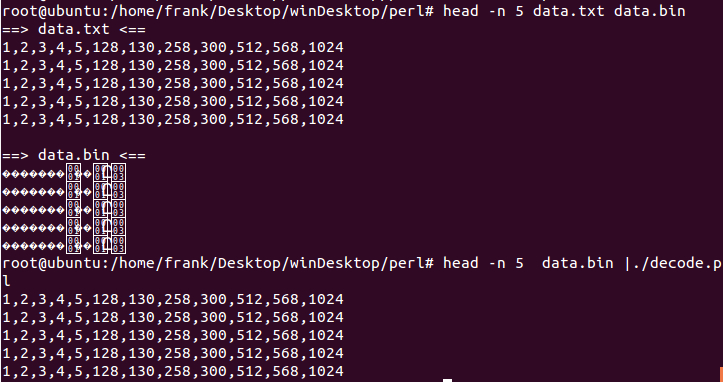
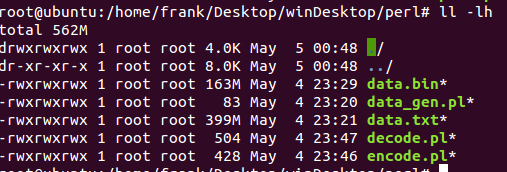
文件已经从399M压缩到了163M,压缩率为(399-163)/399 = 0.59
At 1:03 AM
##参考资料
- 《大规模Web服务开发技术》
